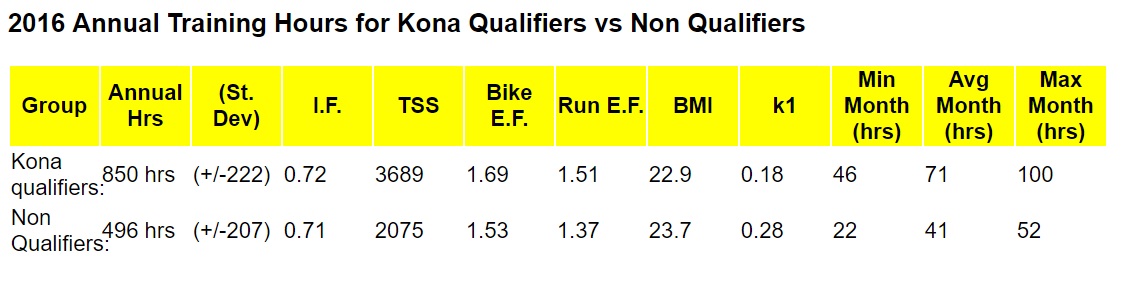
Uitgaande van de gerapporteerde mean en SD en 2000 kwalificerende atletende en 5000 niet-kwalificerende atleten krijg je deze histogrammen:
Laat je daar een t-test op los, of een Kolmogorov-Smirnov test dan is er, ondanks flinke overlap, wel bewijs voor een verschil in mean (t-test) of distributie (KS-test). En er zouden maar heel weinig atleten zijn die meer dan 1000 uur trainen en niet kwalificeren (wat overeenkomt met de ervaring van de coach). En heel weinig atleten die minde dan ~300 uur trainen en wel kwalificeren.
Maar hoeveel atleten heeft deze coach getraind? Het lijkt erop dat hij elke kwalificatie en non-kwalificatie per jaar heeft meegenomen, maar dan heb je data die dependent is. Immers, hij kan een atleet hebben die jaar na jaar met 400 uur zich kwalificeert, en een een atleet die zich jaar na jaar met 900 uur niet kwalificeert.
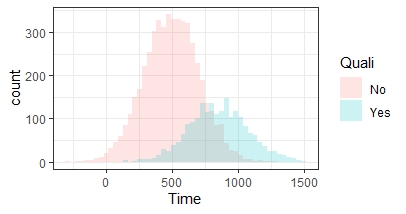
Stel dat de gemiddeldes en verdeling wel gelijk is, maar hij 25 verschillende atleten heeft gehad die zich kwalificeerden en 100 die zich niet kwalificeerden, dan krijg je zo'n histogram, en dat is iets waar ik veel voorzichtiger mee zou zijn om conclusies aan te verbinden.
Ik denk dat consistentie belangrijker is dan totaal aantal uren, al hebben ze natuurlijk wel invloed op elkaar. Je kunt heel lastig heel veel uren maken zonder consistent te zijn. Maar ik denk wel dat iemand die gemiddeld 12 uur per week traint, varierend tussen 10-14 uur per week gemiddeld een grotere kans op kwalificatie heeft dan iemand gemiddeld 12 uur per week traint, maar waar het varieert tussen de 1 en 24 uur per week.